|
Analyzing vast textual data and summarizing key information from electronic health records imposes a substantial burden on how clinicians allocate their time. Although large language models (LLMs) have shown promise in natural language processing (NLP), their effectiveness on a diverse range of clinical summarization tasks remains unproven. In this study, we apply adaptation methods to eight LLMs, spanning four distinct clinical summarization tasks: radiology reports, patient questions, progress notes, and doctor-patient dialogue. Quantitative assessments with syntactic, semantic, and conceptual NLP metrics reveal trade-offs between models and adaptation methods. A clinical reader study with ten physicians evaluates summary completeness, correctness, and conciseness; in a majority of cases, summaries from our best adapted LLMs are either equivalent (45%) or superior (36%) compared to summaries from medical experts. The ensuing safety analysis highlights challenges faced by both LLMs and medical experts, as we connect errors to potential medical harm and categorize types of fabricated information. Our research provides evidence of LLMs outperforming medical experts in clinical text summarization across multiple tasks. This suggests that integrating LLMs into clinical workflows could alleviate documentation burden, allowing clinicians to focus more on patient care. |
 |
| Left: Prompt anatomy for both adaptation methods: in-context learning (ICL, m > 0) and quantized low-rank adaptation (QLoRA, m = 0). Right: We generally find better performance when (1) using lower temperature, i.e. generating less random output, as summarization tasks benefit more from truthfulness than creativity (2) assigning the model clinical expertise in the prompt. |
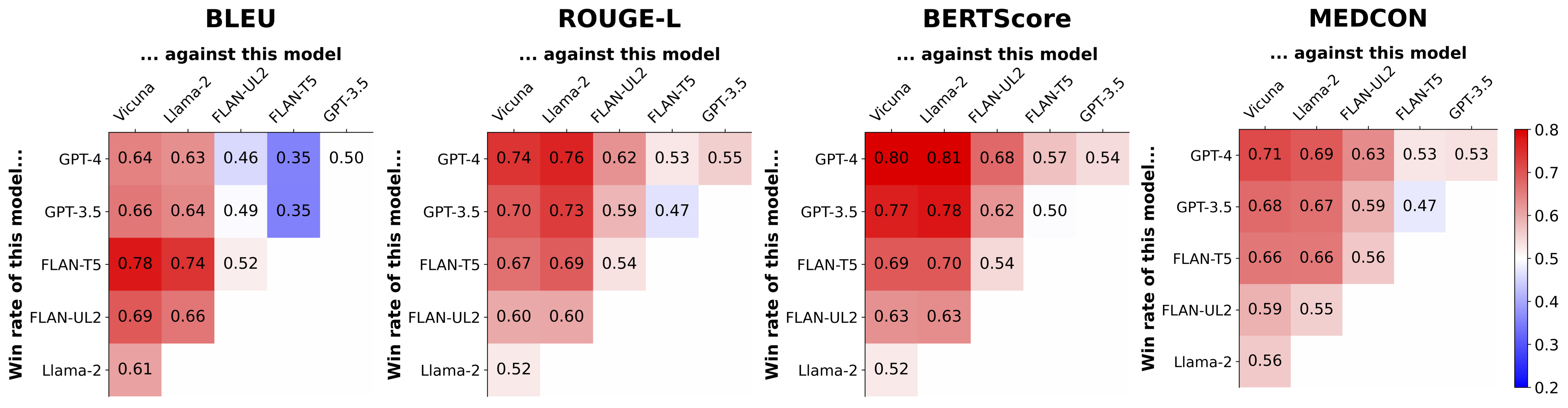 |
| Model win rate: a head-to-head winning percentage of each model combination, where red/blue intensities highlight the degree to which models on the vertical axis outperform models on the horizontal axis. GPT-4 generally achieves the best performance. While FLAN-T5 is more competitive for syntactic metrics such as BLEU, we note this model is constrained to shorter context lengths (see Table 1). When aggregated across datasets, seq2seq models (FLAN-T5, FLAN-UL2) outperform open-source autoregressive models (Llama-2, Vicuna) on all metrics. |
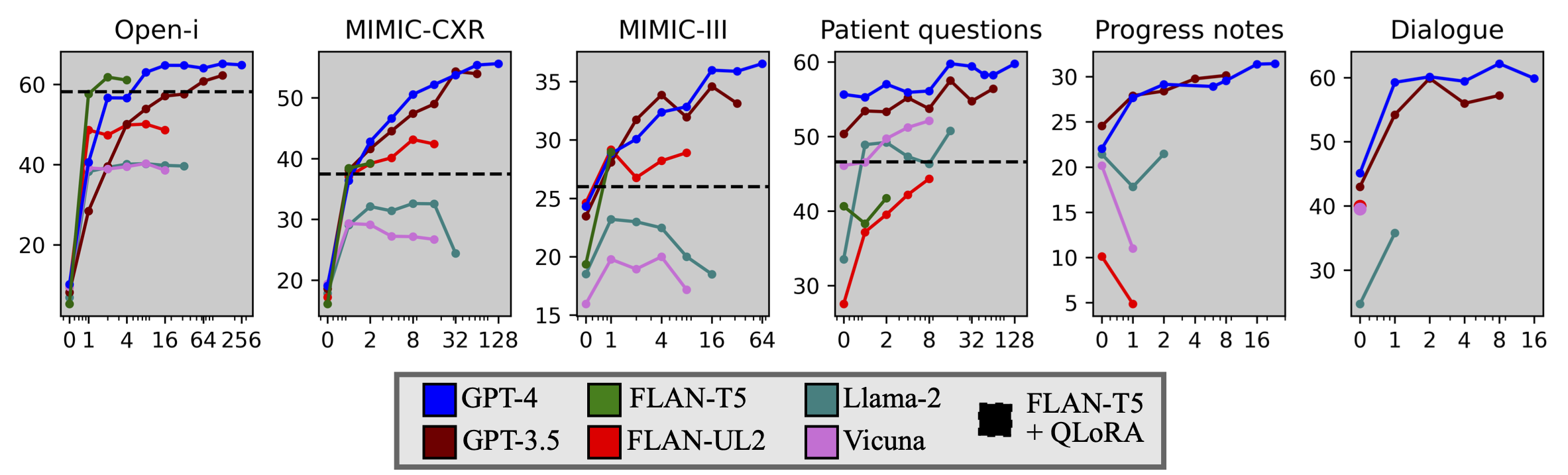 |
| MEDCON scores vs. number of in-context examples across models and datasets. We also include the best model fine-tuned with QLoRA (FLAN-T5) as a horizontal dashed line for valid datasets. Zero-shot prompting (0 examples) often yields considerably inferior results, underscoring the need for adaptation methods. Note the allowable number of in-context examples varies signficantly by model context length and dataset size. See the paper for results across other metrics. |
 |
| Clinical reader study. (a) Study design comparing the summaries from the best model versus that of medical experts on three attributes: completeness, correctness, and conciseness. (b) Results. Model summaries are rated higher on all attributes. Highlight colors correspond to a value’s location on the color spectrum. Asterisks (*) denote statistical significance. (c) Distribution of reader scores. Horizontal axes denote reader preference as measured by a five-point Likert scale. Vertical axes denote frequency count, with 1,500 total reports for each plot. (d) Extent and likelihood of potential medical harm caused by choosing summaries from the medical expert (pink) or best model (purple) over the other. Model summaries are preferred in both categories. (e) Reader study user interface. |
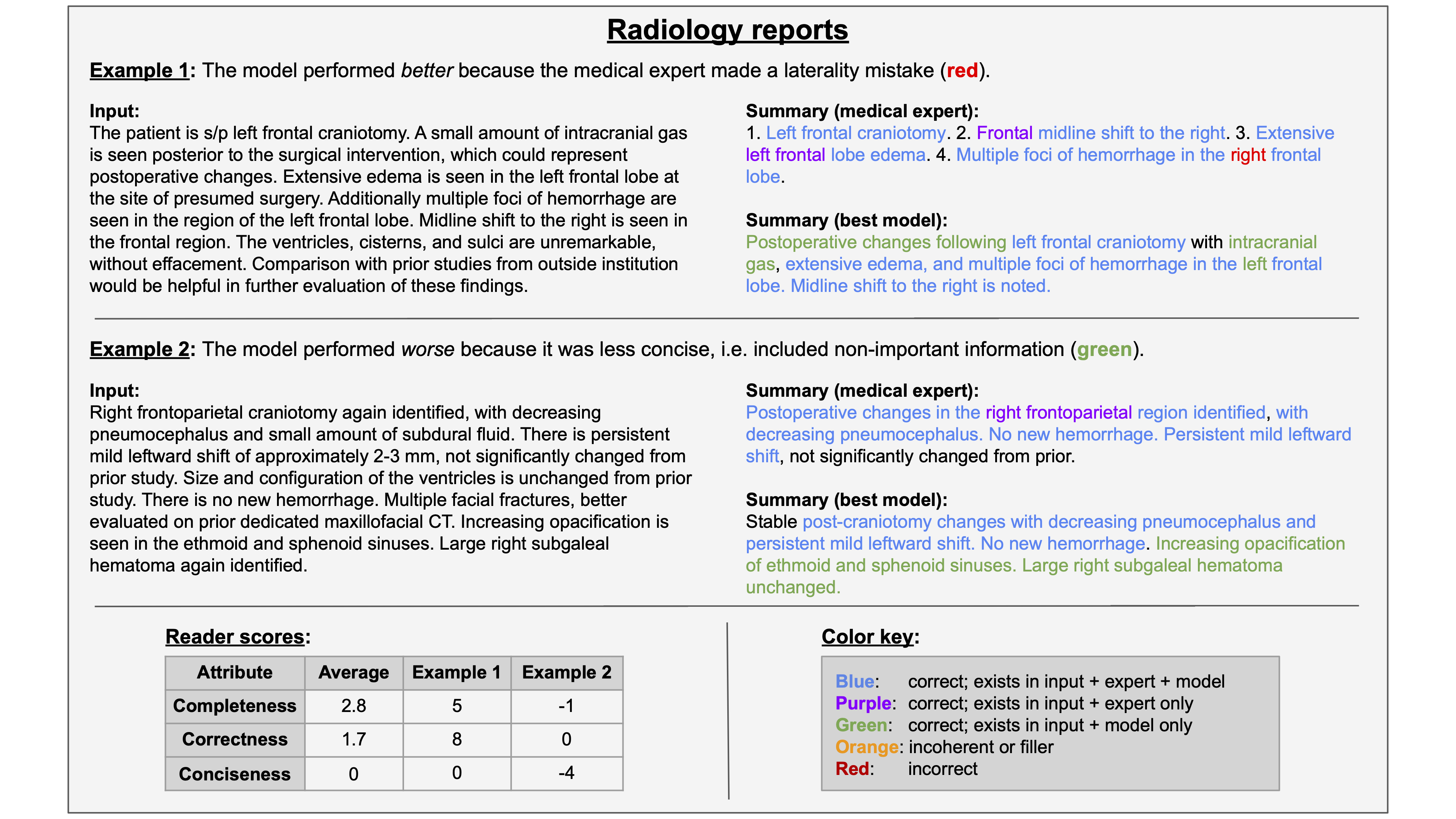 |
| Annotation: radiology reports. The table (lower left) contains reader scores for these two examples and the task average across all samples. Top: The model performs better due to a laterality mistake by the medical expert. Bottom: The model exhibits a lack of conciseness. The table (lower left) contains reader scores for these two examples and the task average across all samples. |
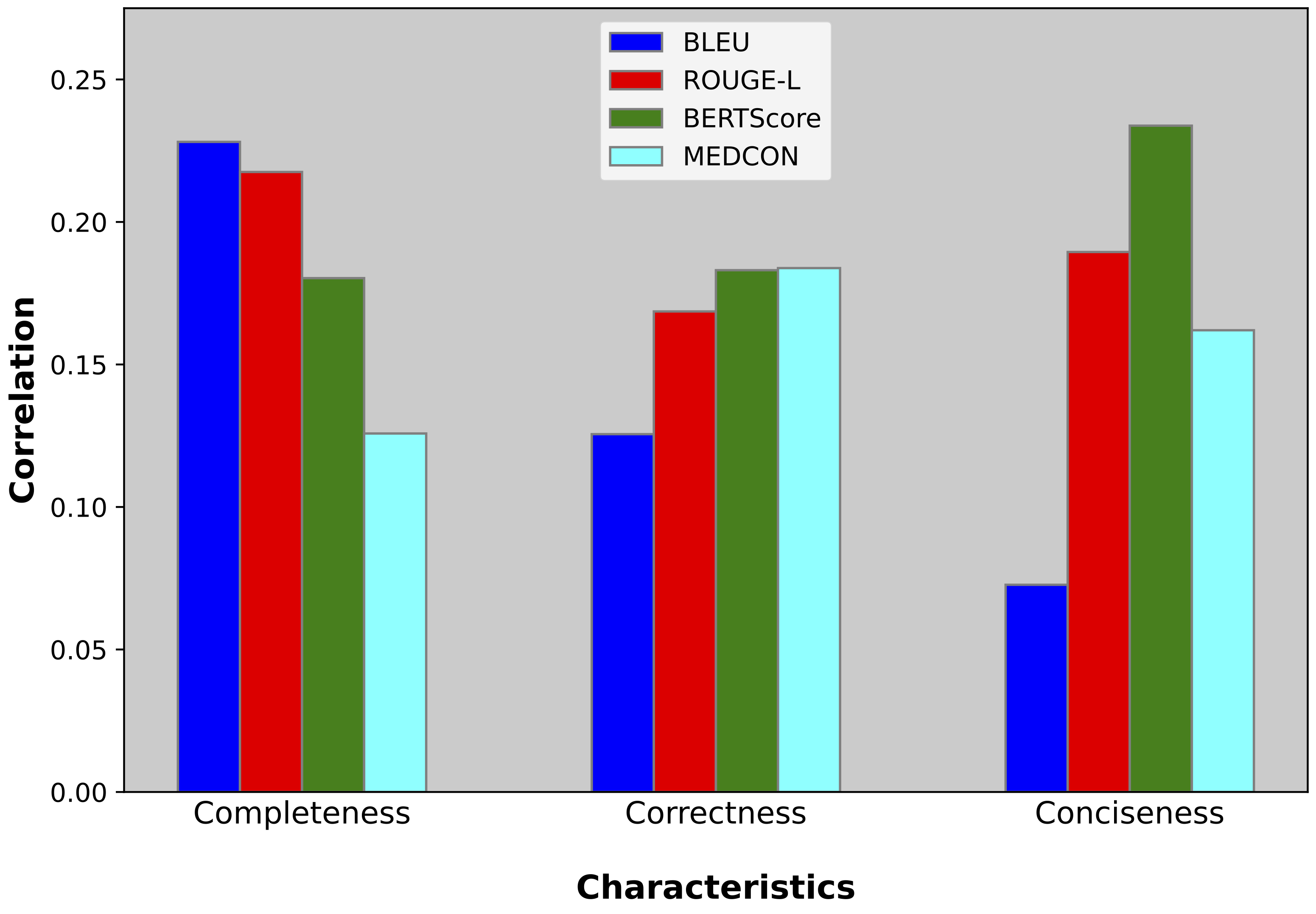 |
| Correlation between NLP metrics and reader scores. The semantic metric (BERTScore) and conceptual metric (MEDCON) correlate most highly with correctness. Meanwhile, syntactic metrics BLEU and ROUGE-L correlate most with completeness. |
 |
D. Van Veen, C. Van Uden, L. Blankemeier, J.B. Delbrouck, A. Aali, C. Bluethgen, A. Pareek, M. Polacin, E.P. Reis A. Seehofnerova, N. Rohatgi, P. Hosamani W. Collins, N. Ahuja, C.P. Langlotz, J. Hom, S. Gatidis, J. Pauly, A.S. Chaudhari Adapted Large Language Models Can Outperform Medical Experts in Clinical Text Summarization 2023. (hosted on ArXiv) |
AcknowledgementsMicrosoft provided Azure OpenAI credits for this project via both the Accelerate Foundation Models Academic Research (AFMAR) program and also a cloud services grant to Stanford Data Science. Further compute support was provided by One Medical, which Asad Aali used as part of his summer internship. Curtis Langlotz is supported by NIH grants R01 HL155410, R01 HL157235, by AHRQ grant R18HS026886, by the Gordon and Betty Moore Foundation, and by the National Institute of Biomedical Imaging and Bioengineering (NIBIB) under contract 75N92020C00021. Akshay Chaudhari receives support from NIH grants R01 HL167974, R01 AR077604, R01 EB002524, R01 AR079431, and P41 EB027060; from NIH contracts 75N92020C00008 and 75N92020C00021; and from GE Healthcare, Philips, and Amazon. |